

Abstract
Objective. Observational axial spondyloarthritis (axSpA) research in large datasets has been limited by a lack of adequate methods for identifying patients with axSpA, because there are no billing codes in the United States for most subtypes of axSpA. The objective of this study was to develop methods to accurately identify patients with axSpA in a large dataset.
Methods. The study population included 600 chart-reviewed veterans, with and without axSpA, in the Veterans Health Administration between January 1, 2005, and June 30, 2015. AxSpA identification algorithms were developed with variables anticipated by clinical experts to be predictive of an axSpA diagnosis [demographics, billing codes, healthcare use, medications, laboratory results, and natural language processing (NLP) for key SpA features]. Random Forest and 5-fold cross validation were used for algorithm development and testing in the training subset (n = 451). The algorithms were additionally tested in an independent testing subset (n = 149).
Results. Three algorithms were developed: Full algorithm, High Feasibility algorithm, and Spond NLP algorithm. In the testing subset, the areas under the curve with the receiver-operating characteristic analysis were 0.96, 0.94, and 0.86, for the Full algorithm, High Feasibility algorithm, and Spond NLP algorithm, respectively. Algorithm sensitivities ranged from 85.0% to 95.0%, specificities from 78.0% to 93.6%, and accuracies from 82.6% to 91.3%.
Conclusion. Novel axSpA identification algorithms performed well in classifying patients with axSpA. These algorithms offer a range of performance and feasibility attributes that may be appropriate for a broad array of axSpA studies. Additional research is required to validate the algorithms in other cohorts.
Big data research is important for studying uncommon outcomes and diseases in real-world settings1. In particular, there are tremendous opportunities to improve knowledge gaps with axial spondyloarthritis (axSpA) with big data research, because axSpA concepts have broadened in recent years2,3. With advances in imaging and treatment, it became apparent in the 2000s that a large proportion of people with axSpA phenotypes were unrecognized because their diseases were inconsistent with traditional concepts of axSpA. Despite widespread acceptance of the broader axSpA concepts, big data axSpA research continues to be constrained by outdated axSpA definitions, because International Classification of Diseases, 9th and 10th revisions (ICD-9 and ICD-10) billing codes exist only for the traditionally recognized phenotype of ankylosing spondylitis (AS)4,5,6,7,8. Thus, nearly one-half of the 3.2 million Americans with axSpA have been excluded from big data axSpA research9,10, and there are insufficient data with important outcomes such as mortality, comorbidities, and healthcare use in axSpA populations8.
Cohort identification is additionally challenging for axSpA because the nomenclature surrounding axSpA is diverse and evolving11. The term axSpA was introduced in 200912, when it became apparent that many patients with axSpA phenotypes were not identified with traditional criteria for SpA in the axial skeleton13. Since then, new terms have been coined to describe axSpA phenotypes14, and the use of axSpA terms has varied widely among patients, providers, and other interested parties.
With other conditions, various approaches have been used for cohort identification, when billing codes were insufficient. The most common include rule-based approaches and natural language processing (NLP)15. With a rule-based approach, combinations of structured (coded) data may be used to identify patients with a specific condition. For example, ICD codes, disease-modifying antirheumatic drugs (DMARD), and laboratory data [rheumatoid factor or anticyclic citrullinated peptide antibodies (anti-CCP)] were used to identify patients with rheumatoid arthritis (RA)16. With NLP, computers can be trained to identify language in the free text of clinical documents that indicates the presence of specific conditions. For example, computers may be trained to identify variations of the term rheumatoid arthritis and to use the surrounding text to classify the terms as “yes” (RA present) or “no” (RA not present).
Our goal was to develop accurate methods for identifying patients with axSpA in large datasets. Given the challenges with insufficient billing codes and evolving axSpA nomenclature, we elected to use a combination of coded and NLP data. In our previous work, we first described the development of 3 NLP algorithms that accurately classified axSpA concepts, including diagnostic language (spond*) and key disease features (sacroiliitis and HLA-B27 positivity)17. Second, we described our strategy and processes for establishing an appropriate sample of patients for developing and testing axSpA identification algorithms18. In this third stage of developing axSpA identification methods, the objectives were to develop and validate algorithms to accurately classify patients as having or not having axSpA.
MATERIALS AND METHODS
Design, setting, and data sources
This study used historical data from veterans enrolled in the US Veterans Health Administration (VHA). The data source was the Corporate Data Warehouse, a national repository of data from the VHA medical record system and other VHA clinical and administrative systems19. The patient Integration Control Number was used to link patients across VHA stations. Data were housed and analyzed within the Veterans Affairs (VA) Informatics and Computing Infrastructure20. This research was conducted in compliance with the Helsinki Declaration, with the approval of the University of Utah Institutional Review Board (IRB_00052363).
Population
The study population consisted of 600 veterans enrolled in the VHA between January 1, 2005, and June 30, 2015. A detailed description of this patient sample and the processes for selection and chart review of the sample was previously published19. In short, a risk-stratified approach to selecting patients was applied that enriched the population with patients at high risk of axSpA to ensure that a sufficient number of patients in the sample had axSpA. To maximize generalizability, patients at low risk for axSpA were also included. Risk was assigned according to variables that clinical experts anticipated to be associated with high, intermediate, and low risk for axSpA. Veterans with HLA-B27 positivity or ≥ 1 AS ICD-9 code were assigned to the high-risk stratum. Veterans with ≥ 1 ICD-9 code for a non-AS SpA subtype or sacroiliitis were assigned to the moderate-risk stratum. Veterans with ≥ 1 ICD-9 code for a SpA mimic or chronic back pain were assigned to the low-risk stratum. From each stratum, 200 veterans (600 total) were randomly selected into the study sample.
Rheumatologist chart reviewers classified the 600 sampled veterans as having or not having axSpA, according to expert opinion and chart review guidelines (Supplementary Data 1, available with the online version of this article). Of the 600 sampled patients, 162 (27.0%) had axSpA and 438 (73.0%) did not have axSpA. Among the 162 patients with axSpA, 125 (77.2%) were from the high-risk stratum, 34 (20.1%) were from the moderate-risk stratum, and 3 (1.9%) were from the low-risk stratum. Among the 438 patients without axSpA, 75 (17.1%) were from the high-risk stratum, 166 (37.9%) were from the moderate-risk stratum, and 197 (45.0%) were from the low-risk stratum. The sample of 600 chart-reviewed patients was randomly subdivided into a training set (n = 451) for algorithm development and a testing set (n = 149) for independent validation of the algorithms.
Variables
Clinical experts selected 49 variables anticipated to be useful in differentiating people with axSpA from people without axSpA. These variables included both structured data and extracts from unstructured medical notes. Structured data included diagnosis codes (Supplementary Table 1, available with the online version of this article) for SpA and overlapping conditions (AS, undifferentiated SpA, Crohn disease, uveitis, back pain, etc.), laboratory data relevant to SpA [C-reactive protein (CRP), erythrocyte sedimentation rate (ESR), HLA-B27], medications frequently used to treat SpA (biologic and synthetic disease-modifying antirheumatic drugs), healthcare use patterns (no. rheumatology visits, no. visits with other provider types), and comorbidities as measured by the Rheumatic Disease Comorbidity Index (RDCI)21. NLP was used to extract information not readily available in structured data, including the concepts of sacroiliitis, HLA-B27 positivity, and terms containing the “spond-” prefix.
Algorithm development and validation
Three algorithms were developed including the Full algorithm, the High Feasibility algorithm, and the Spond algorithm (R code in Supplementary Data 2, available with the online version of this article)22. The Full algorithm is the most inclusive and resource-intensive with 3 NLP algorithms and 46 coded variables. The High Feasibility algorithm included only 16 coded variables. The Spond NLP algorithm included only the NLP algorithm for Spond. Random Forest and 5-fold cross validation were used to develop and test the Full algorithm and High Feasibility algorithm23,24,25,26. To reduce bias, out-of-bag error estimates were used within the training subset (n = 451)23. Random Forest was not necessary for the Spond NLP algorithm, because it was treated as a single variable.
The development of the NLP algorithms was described in a previous publication18. In short, terms representing the concepts of SpA, sacroiliitis, and HLA-B27 positivity were explored by clinical experts, and sections of text containing clinically meaningful terms (snippets) were extracted from clinical notes. With annotation, clinical experts reviewed the snippets and classified them according to whether they represented the intended axSpA concept. With supervised machine learning on the annotated snippets, computers were trained to replicate the clinical experts’ snippet classifications (Library for Support Vector Machines, version 3.21)27. The accuracies of the NLP algorithms in an independent dataset of annotated snippets were 91.0% for Spond, 92.0% for sacroiliitis, and 99.0% for HLA-B27 positivity. The Spond NLP was used in 2 ways. In the Full algorithm, it served as a variable, in combination with the 46 coded variables and the 2 other NLP variables. Since our preliminary assessment of the Spond NLP suggested that it performed well independently of other variables, it was also validated in this study population as a standalone instrument for classifying patients as having or not having axSpA.
For the High Feasibility algorithm, variables were selected according to importance rankings determined with Random Forest Mean Decrease Gini scores that take into account the magnitude of effect and frequency of each variable in the population28. The 3 NLP variables were excluded because they were more resource-intensive to apply than the coded variables. The remaining 46 coded variables were ranked from highest to lowest importance. Error rates were calculated for 46 candidate algorithms that ranged in size from 1 coded variable to 46 coded variables. The lowest error rate was balanced with the lowest number of coded variables to select the candidate algorithm that served as the High Feasibility algorithm.
Statistics
Sensitivity, specificity, positive predictive value (PPV), and negative predictive value (NPV) were used to assess the performances of the algorithms and the AS ICD-9 codes. Performance was also measured with concordance (accuracy), discordance (percentage of population with false-positive and false-negative classifications), and receiver-operating characteristic (ROC) curves29. CI were determined with bootstrapping, with sampling with replacement of the observed data 500 times30.
RESULTS
Population
Among the 600 veterans selected for chart review, 162 (27%) were classified as having axSpA (Yes axSpA), and the remaining 438 (73%) were classified as not having axSpA (No axSpA). Compared to the No axSpA group, the Yes axSpA group had a younger mean age, a higher percentage of males, a lower percentage of CCP positivity, a higher percentage with HLA-B27 testing, and a higher percentage with DMARD exposure. Demographic details and other characteristics of the subjects are in Table 1.
Demographics, characteristics, and healthcare use in sample of veterans at risk for axSpA.
Variable selection for the High Feasibility algorithm
The variables with the highest Random Forest Mean Decrease Gini importance scores were selected for the High Feasibility algorithm (Figure 1). The number of AS ICD-9 codes and number of rheumatology visits during the study period had the highest importance scores. Additional variables ranked among the top 16 most important included number of tests for inflammatory markers (CRP, ESR), number of provider visits (any specialty), exposure to a biologic DMARD, age, geographic region, duration of VA system use, HLA-B27 result, and number of ICD-9 codes indicative of various axial skeleton conditions.

Variables in High Feasibility algorithm according to Random Forest importance scores. ICD9: International Classification of Diseases, 9th revision; CRP: C-reactive protein; DMARD: disease-modifying antirheumatic drug; ESR: erythrocyte sedimentation rate; VA: Veterans Affairs; DISH: diffuse idiopathic skeletal hyperostosis.
Performance of axSpA identification methods: traditional methods
In the subset of patients at risk for axSpA who were not selected to the study population specifically because of an AS ICD-9 code (n = 500), the sensitivity, specificity, PPV, and NPV of an AS ICD-9 code for axSpA were 57.3%, 96.9%, 76.8%, and 92.8%, respectively.
Performance of axSpA identification methods: novel methods
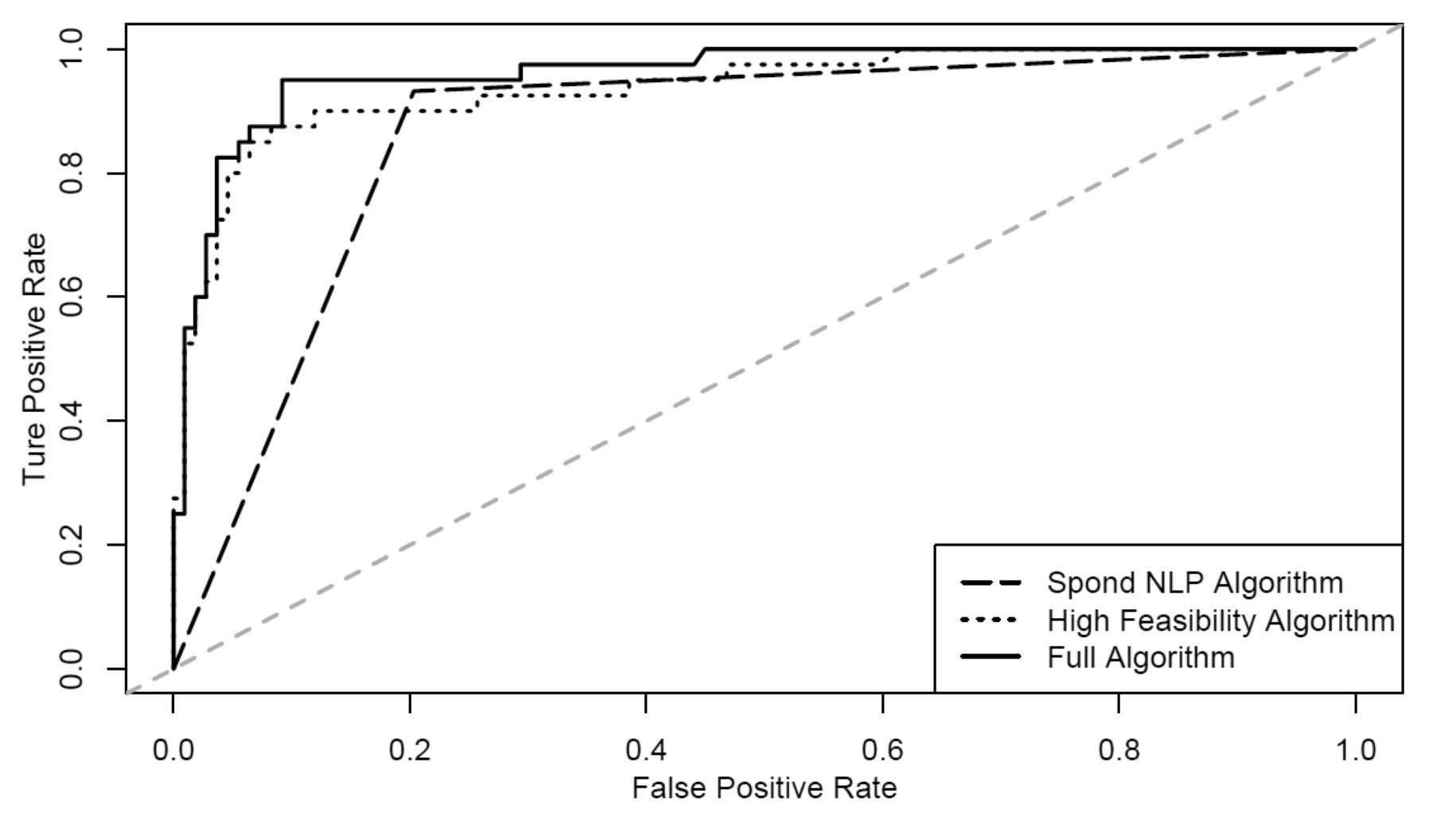
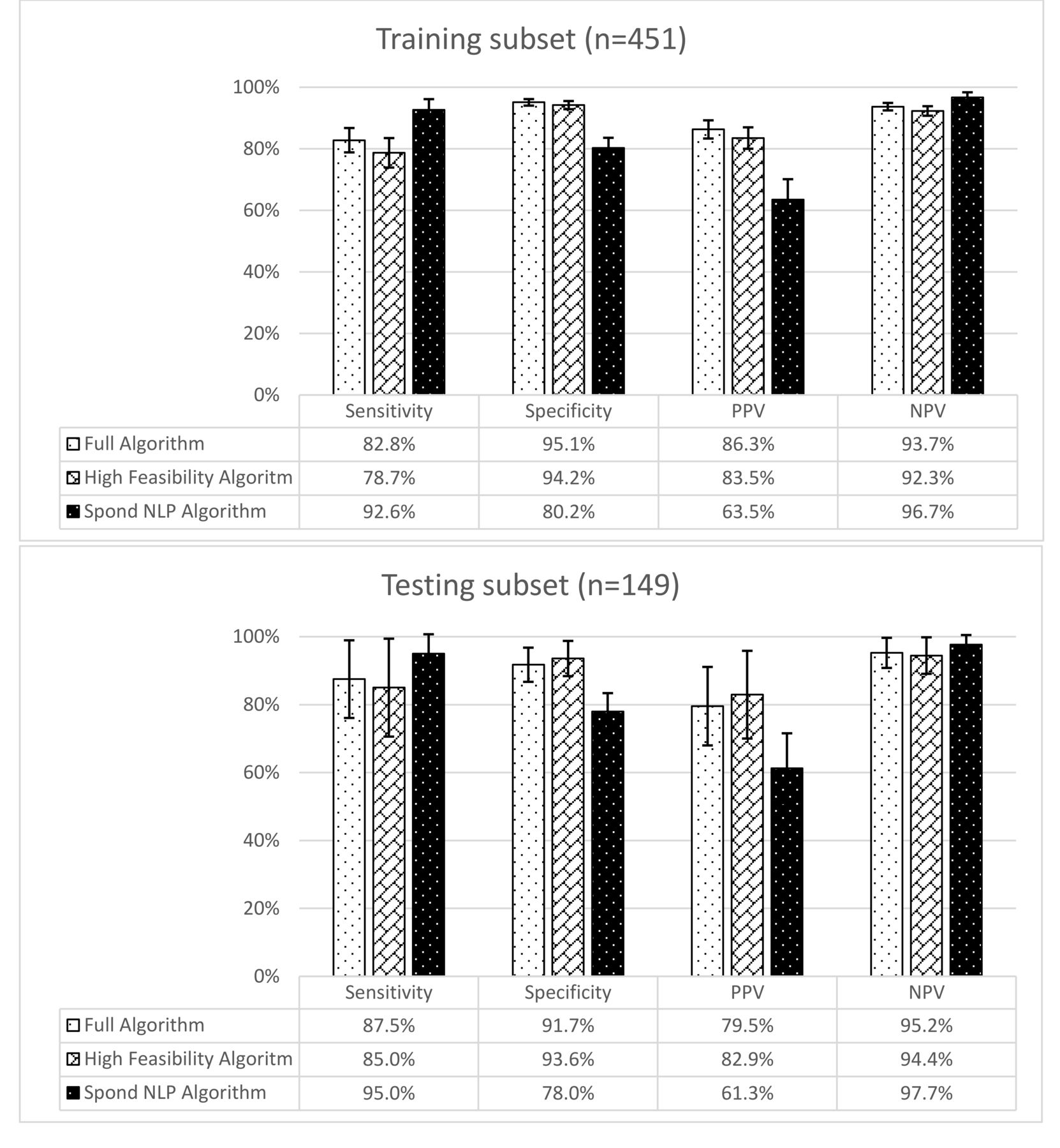
In the testing subset, the areas under the curve with the ROC analysis for the Full algorithm, High Feasibility algorithm, and Spond NLP algorithm were 0.96, 0.94, and 0.86, respectively (Figure 2). The sensitivity, specificity, PPV, and NPV were similar in the training and testing subsets 0.86, High Feasibility algorithm 0.94, Full algorithm 0.96. NLP: natural language processing. (Figure 3). In the testing subset, the sensitivity, specificity, PPV, and NPV of the Full algorithm were 87.5%, 91.7%, 79.5%, and 95.2%, respectively. For the High Feasibility algorithm, the sensitivity, specificity, PPV, and NPV were 85.0%, 93.6%, 82.9%, and 94.4%, respectively. For the Spond NLP algorithm, the sensitivity, specificity, PPV, and NPV were 95.0%, 78.0%, 61.3%, and 97.7%, respectively.

Receiver-operating characteristic curves in the testing subset (n = 149). Area under the curve: Spond NLP algorithm 0.86, High Feasibility algorithm 0.94, Full algorithm 0.96. NLP: natural language processing.
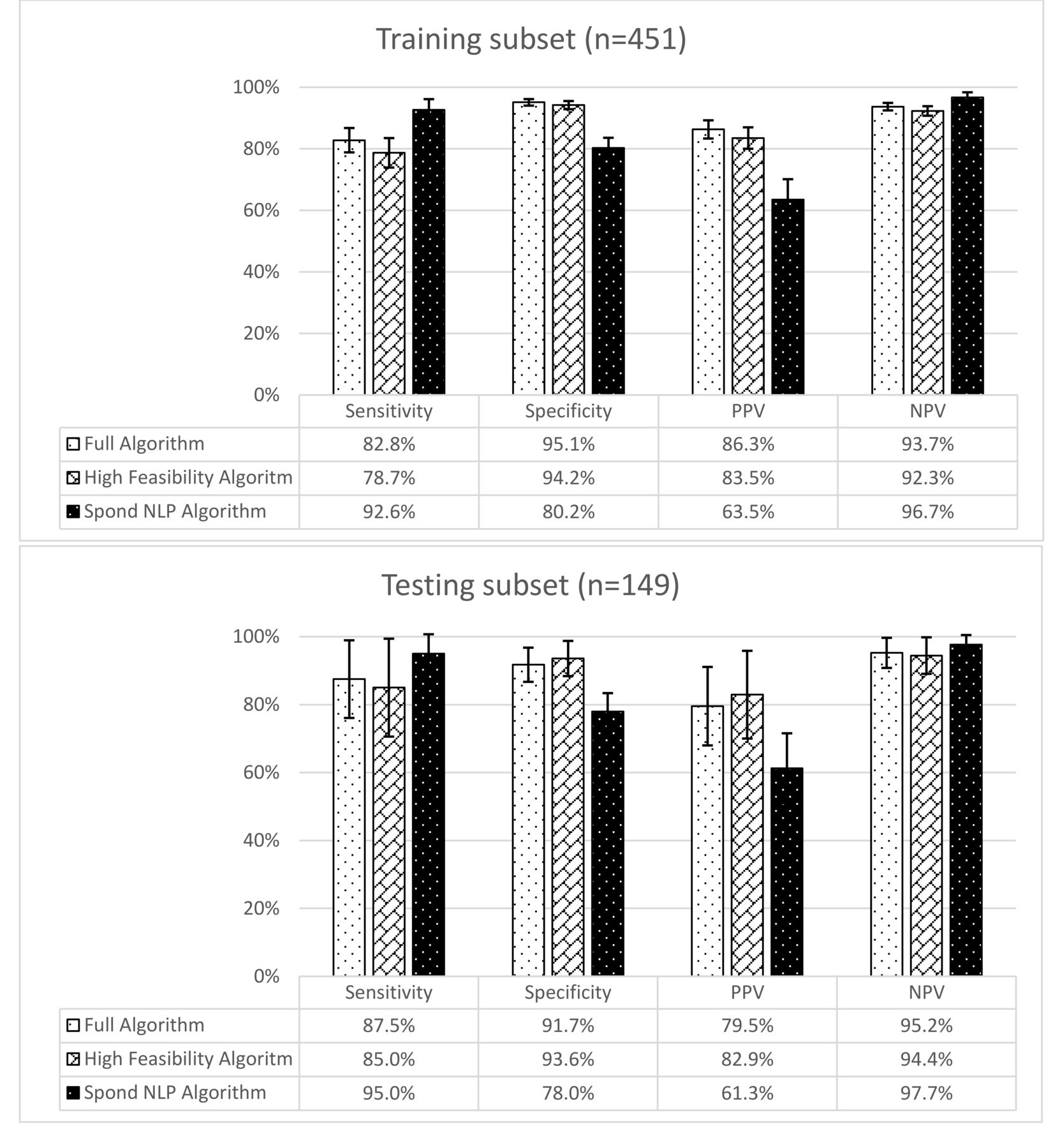
Sensitivity, specificity, PPV, and NPV of axial spondyloarthritis identification methods. PPV: positive predictive value; NPV: negative predictive value; NLP: natural language processing.
The classification concordance (accuracy) was also similar in the training and testing subsets (Figure 4). In the testing subset, concordance was achieved with 90.6%, 91.3%, and 82.6% of patients with the Full algorithm, High Feasibility algorithm, and the Spond NLP algorithm, respectively. The percentages of the population with false-positive and false-negative classifications were similar (3.4%–6.0% testing subset) for the Full algorithm and the High Feasibility algorithm. With the Spond NLP algorithm, the percentage of false positives was higher than the percent of false negatives (16.1% vs 1.3% testing subset).
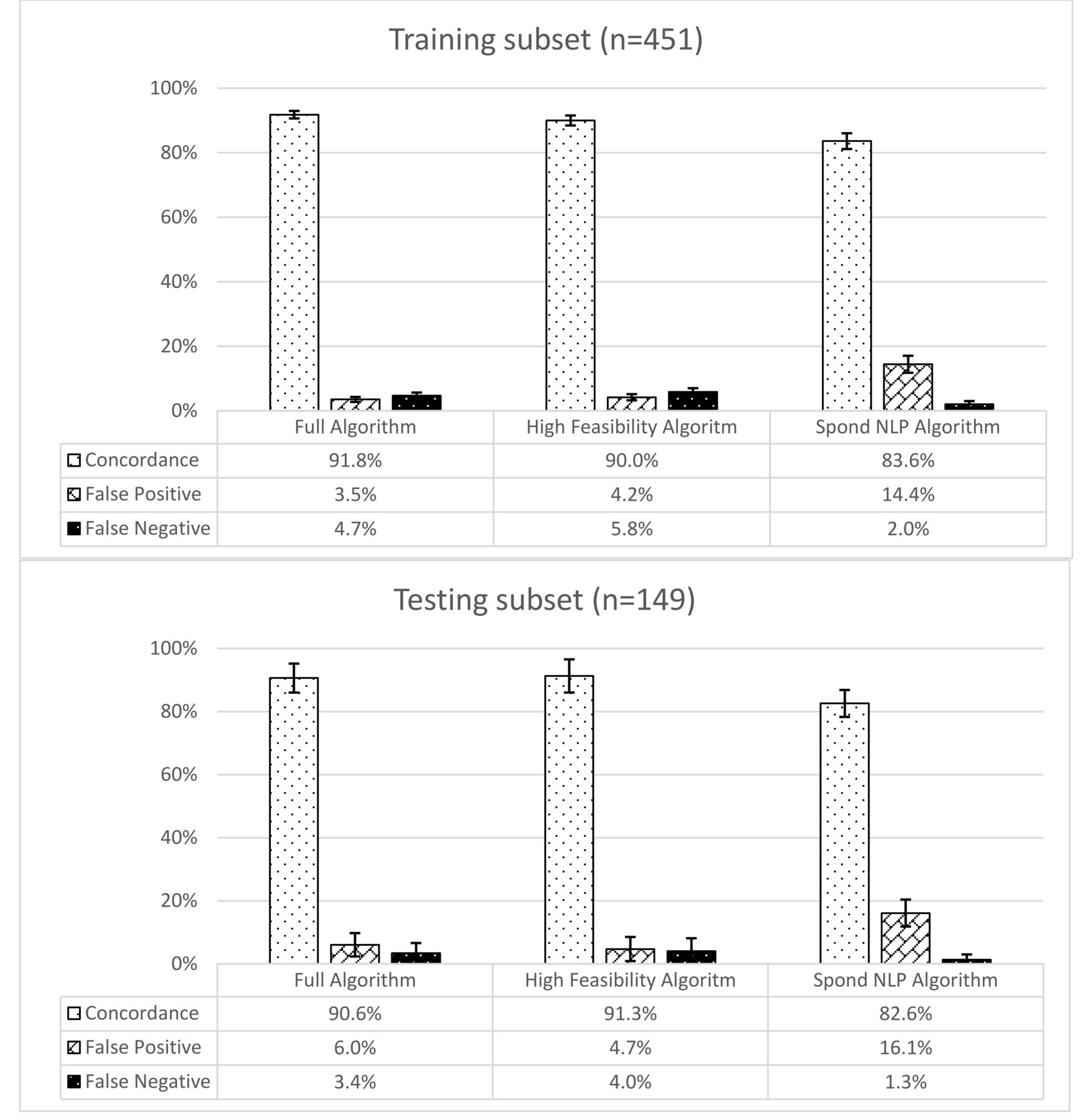
Algorithm concordance (accuracy) with axial spondyloarthritis classification by chart review. NLP: natural language processing.
DISCUSSION
We developed novel methods for identifying patients with axSpA. These methods will enable the development of more inclusive axSpA cohorts than traditional cohort identification methods and may be used to study a variety of poorly understood outcomes in axSpA, such as mortality, comorbidities, treatment patterns, healthcare use, and costs.
With other conditions, cohort identification methods have been applied that similarly used combinations of structured (coded) data and unstructured data from clinical notes. For example, coded data and simple queries in the text of clinical documents were used to identify dialysis patients, with precision (PPV) of 78.4% and recall (sensitivity) of 100%31. Structured data and unstructured data were also successfully used to identify patients eligible for clinical trials (ROC = 0.95)32. In another study, NLP methods were compared to structured data extraction methods for identifying patients undergoing diabetic dialysis; the NLP methods were more sensitive than the coded data extraction methods (89.4% vs 54.9%)16. These studies demonstrated that methods using unstructured data (simple queries and NLP) are useful in cohort identification and may be particularly powerful when combined with structured data extraction methods.
The algorithms developed in our study differ in their performance and feasibility and may be used for different purposes. The Full algorithm and the High Feasibility algorithm had high specificity and may be implemented when low false-positive rates are desired (i.e., treatment considerations). Conversely, the Spond NLP model was more sensitive and may be best when more inclusive identification is desired (i.e., screening for people at high risk of axSpA). The High Feasibility algorithm is the simplest to use and may be applied and tested relatively easily in different datasets.
Strengths of our study include the use of robust, well-characterized data. The study sample was classified and phenotyped by rheumatologist chart reviewers specializing in SpA19. The NLP variables were highly accurate and previously validated in a population of veterans18. Methods for extracting, cleaning, and interpreting the coded variables used in this project were also evaluated and refined for the study population19,33,34,35,36,37.
Limitations of our study include the limited generaliz-ability of the algorithms to other datasets. While the chart-reviewed population in which the algorithms were developed was designed to maximize both feasibility and generalizability, this population is not identical to the general veteran population. Currently the algorithms can be applied to VA populations at risk for axSpA who are selected in the same manner that the chart-reviewed population was selected (with specific variables associated with high, moderate, and low risk of axSpA). To bypass this initial selection step and make the algorithms generalizable to the general veteran population, the algorithms may be tested and refined in that population. Likewise, the VA population is different from other large data populations and the algorithms will require testing prior to use in non-VA datasets.
Another limitation is that the algorithms with NLP (Full algorithm and Spond algorithm) are relatively resource-intensive when applied on a large scale, requiring both bioinformatics expertise and computing resources. Further, the PPV in this study population were likely overestimated relative to the general population and the NPV were likely underestimated, because disease prevalence influences predictive values and the study population was enriched for axSpA. The Full and High Feasibility algorithms were also limited in that they were not inclusive of ICD-10 codes, because ICD-10 codes were not yet implemented in clinical practice during the study period.
Novel methods for accurately identifying patients with axSpA in a large dataset were developed. Compared to traditional methods of cohort identification, the novel methods were more inclusive (sensitive) and more representative of the broadening concepts of axSpA. Additional research is required to apply these methods to other populations to facilitate a wide range of previously impractical big data research in axSpA.
ONLINE SUPPLEMENT
Supplementary material accompanies the online version of this article.
Footnotes
This study was funded by the Marriott Daughters Foundation and the Rheumatology Research Foundation.
- Accepted for publication February 20, 2019.








{kind=link}
{kind=link}
{kind=link}
{kind=link}